Whenever you’re developing software, a certain amount of refactoring and rewriting is inevitable. This is sometimes due to a new idea that will simplify the design or a change to the project requirements. But unfortunately, it often also happens because of a misunderstanding about how the software will connect and interact with its external environment. While it’s impossible to completely avoid such miscommunication, you can minimize it by using a principle I call writing software from the outside in.
The outside-in principle is implicit in a number of programming practices and methodologies that work at different scales, and I’ll mention a few of them below. But explicitly identifying the general principle should allow you to both better understand these methodologies and extend the benefits to other areas that they don’t cover.
Below, I will explain what I mean by the outside and the inside of a coding project, and why the most interesting part is usually the inside. Then I’ll argue that resisting the temptation to start with the interesting part can often save you time and energy in the long run. I will end by discussing different situations where this strategy may or may not make sense.
An Example
To better understand what I mean by writing from the outside in, let’s imagine that you’re building an API for the autocomplete functionality of a web form. The frontend will make calls to the API as the user is typing, and the API will return a list of suggested completions, from a pre-determined list of terms. This example will seem somewhat contrived, but the general pattern of the story is common, particularly in more complex projects.
We can break the autocomplete project into two parts: A function that looks up the terms in the pre-determined list, and the API wrapper that handles the HTTP calls, passing them on to the function. The API wrapper will interact with both the lookup function and the frontend client, and must be compatible with the technical specs of both. The lookup function only interacts with the API wrapper, and you control the spec for this interaction. So the lookup function is on the inside of the project, while the wrapper that interacts with components you don’t control is on the outside.
The API wrapper is fairly standard and will probably be just a few lines of code using an existing library. The lookup function, on the other hand, will require some non-trivial optimizations to get it to scale, maybe involving a B-tree or some other interesting data structure. So your instinct is probably to write that first. Let’s see what happens if we start by writing a function that takes the beginning of a word and returns all the words on the given list that have that prefix.
Once that’s done we can write the API wrapper. But when we start working with the client calls, we run into an issue: The client doesn’t send everything the user has typed. It only sends the last character and a UUID for the session. The backend server will need to keep track of what each user has typed so far in their session.
This misunderstanding completely changes the nature of the project: We now need a way to track sessions on the backend, but on the other hand we could potentially use this to make the lookup algorithm more efficient by storing a pointer into the B-tree for each session. Either way, we’re going to have to completely rewrite the function.
Yes, we could (and probably should) rewrite the client to send the whole thing. And yes, we should’ve figured this out before we even started the project. But on more complex projects, it often isn’t possible to modify the external specs, and these specs are complex enough that you can easily miss small details with a large impact.
What it Means
Without the sort of very detailed API specification that you might use with the waterfall methodology, most of the details about how your code will interact with external systems will be implied rather than explicit. You will have to make assumptions, often without even realizing it, and these may be different than those of the developers on the other end. These details will be worked out as you go along, typically at the time you implement those particular interactions.
Each layer of the project defines the specification for the next inner layer. And while you control these inner specs, they’re limited by the outer spec of each layer. So if your understanding of the outer spec changes, it will force you to change your assumptions about the inward facing spec, which can cascade to other inner layers. By working through the details of the outer layer before you’ve written the inner layers, you minimize the risk of having to rewrite them because your understanding has changed.
Note that this does not replace or negate the strategy of starting with a Minimum Viable Product (MVP). An MVP will have all the layers of a final product, but a very narrow slice of each. If you think of the project’s layers as concentric circles, an MVP looks like a small number of narrow bands that connect the center circle to the external dependencies on the outer circle. The outside-in principle suggests that as you build your MVP, you should start at the outer end of each band and work inwards. Then as you expand the MVP by widening each band, you’ll start at the outside and expand inwards.
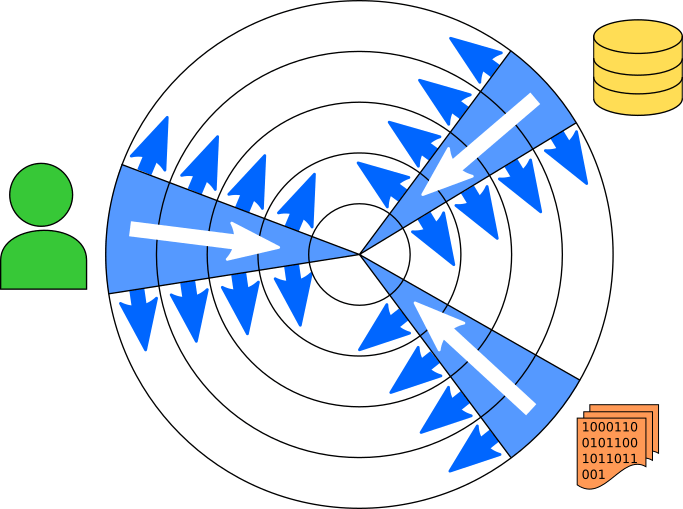
In fact, the purpose of the MVP is closely related to the outside-in principle, in that it prevents you from getting too far on the inner layers before you nail down the outer ones. But even on a project as minimal as an MVP, you need to start writing code somewhere, and that should be on the outside.
Test Driven Development (TDD) is also motivated in part by the outside-in principle: By writing the test first, you force yourself to understand the interface with the next outer layer before you work on the interior logic. But while TDD works at the level of a single layer, the outside-in principle applies across layers as well. At this level, the outside-in principle motivates variants of TDD such as Documentation Driven Development and Demo Driven Development.
The external connections that define the outer layer depend on the type of project. For UI work, it’s the user and the backend API. For a web backend, it’s the frontend client and the database(s). For ML models, it’s data sources and the APIs for reporting results. If you look back at projects you’ve worked on, there’s a good chance you’ll be able to identify multiple layers with an inside and outside, no matter how simple they were.
Working from the outside in may require that you mock out the inner layers as you go, similar to TDD. And as with TDD, this both forces you to think more carefully about these interfaces and can leave you with a useful tool for identifying and fixing bugs later on. This is also common in UI development, where one tries to get user feedback on a prototype with mocked data/backend as early in the process as possible.
As you complete each layer, its inward-pointing interface becomes the external interface for the next layer. The mock you built for this next layer becomes a detailed spec for how the layer should behave.
Why it Matters
As with the autocomplete example above, the most interesting part of a coding project is usually the inside. The outer layers tend to be abstractly generic things like reformatting and transferring data. The logic that’s unique to the project is usually on the inside.
This also means it’s more likely you’ll have open questions about how, or even if, you’ll get the inside layer to work. So the temptation is to write the inside first to resolve these questions.
Starting from the outside, there’s still a risk of wasted work if you can’t get the inside to work. However, in my experience there is typically more flexibility in how you write the inner layers, and greater risk of making incorrect assumptions about external interfaces. In fact, if you haven’t built the outside, there’s no way to be sure you’ve written the inside to solve the correct problem, let alone solve it correctly.
If you really are unsure if your approach for the inside will work, you can start with a Proof of Concept (PoC). This will still have an outside which defines the criteria for telling if it succeeded, but the outside layers are much thinner than for the full project, and written so that you won’t mind throwing them away if it fails. In fact, since the external interfaces of a PoC are typically quite different from the final implementation, the expectation should be that the whole thing will be rewritten.
Caveats
The outside-in principle is based on certain assumptions about the context of your project, and may not make sense in cases where these assumptions don’t hold. In particular, it assumes that the goal of the project is linked to external requirements and specifications that are outside your control.
One situation where this won’t be true is when you’re writing code in order to learn something — a new algorithm, a new language, or learning to code for the first time. In this setting, the final product doesn’t need to work for it to be a success, and if you run into a conflict with the outer layers, you’ve still learned something. In fact, starting with the outer layers may distract you from the thing you wanted to learn, so you should start on the inside.
In other settings where the principle may seem less necessary, it’s still worth considering what the layers are before you start writing code.
As noted above, even a PoC has external interfaces, and in all but the most trivial cases will have multiple layers.
If you’re developing an ML model, even before you know what model and algorithm you’re going to use, you can write the code for evaluating and presenting the results. In fact, having those outer layers in place by the time you train your first model will allow you to quickly iterate and improve it.
If you’re writing a tool for your own use, to process the output from other code you’ve written, then you have complete control over the external spec. However, you may have forgotten some details about the output and probably haven’t fully thought through how you want the tool to interact with you. So it may still make sense to start from the outside and force yourself to figure it out.
In a research setting, you’ll probably want to mix outside-in and inside-out. For the early, exploratory phases where you’re learning about a problem, you typically won’t know enough to identify what the outside should look like. But once you understand that structure and context, having the outer layers can allow you to quickly iterate and optimize your solution.
Conclusion
The idea of working from the outside in is not new to software engineering. In fact, it’s implicit at different levels in many common software engineering practices including Test Driven Development and Minimum Viable Products. Recognizing it as a principle in its own right will allow you to apply it more broadly, and should spare you some unnecessary code rewriting.
Thanks to Eric Ma, Nathaniel Diamant and Jon Bloom for comments and suggestions on an earlier draft.

2 thoughts on “Writing Software from the Outside In”